

The Smartknife: Data transformation on a budget
The Smartknife: Data transformation on a budget
In part 3 of the Lean Data Stack series, I talk about data transformation tools. Tl;dr: just use dbt.

I mostly write (or plan to) about Data orgs, technology, metrics, and some miscellaneous work-related stuff, with the aim of publishing fortnightly. If you want to read more of my work, please subscribe below. It’s free and I promise not to sell your data to China (unless you’d like me to). You can also find me on LinkedIn and Twitter. Thanks for reading!
Now that our restaurateur has a fridge filled with fresh ingredients, they’re ready to start preparing meals.
Having watched the chefs for a few days, the restaurateur has noticed a few problems:
The chefs do a lot of repetitive work. Chop. Chop. Chop. Chopping the same thing, the same way, time after time. Chop. Chop. Chop.
Training new chefs is hard. The recipes are complex, involving multiple steps that must be done in a certain order. It’s a long time before any new chef is productive.
When things go wrong, it’s hard to know what happened. The chefs each have their own way of doing things, and nothing is written down. Who has time to write things down?
Things do go wrong a lot, and nobody finds out until it’s too late. The restaurant just hospitalised a customer by serving them a vegan keema containing ground walnuts, despite being told in advance about their nut allergy.
Most Data teams have encountered the analog of some or all of these problems. When a Data team is one person, the context of the code behind the data model often exists only in that person’s head, rather than being documented. This makes an effective handover impossible, and leads to hours of debugging when things go wrong.
A cautionary tale
I built the first version of Impala’s data transformation processes using scheduled queries in Google BigQuery - a vast web of CREATE OR REPLACE TABLE statements, running according to a predetermined schedule.
This was an attractive option at first. It costs only as much as the queries cost to run, and doesn’t require a subscription to any third-party tools. For somebody who knows SQL and has a good enough understanding of data modelling, it’s a simple option.
This approach works fine, up to a point. If the dependencies between your prepared tables and raw tables are simple, and you’re the only person working on the data pipelines, you can get away with this. You will usually have enough context to debug, and make incremental improvements where necessary. You built it all yourself, after all.
The problems begin to creep in when things change, which, at an early-stage company, they almost certainly will on a regular basis, perhaps in the following ways:
The company launches a new product, or changes the pricing model of an existing product.
An existing business process changes, meaning that the representation of that process in your data warehouse no longer reflects reality.
The structure of a raw data source changes, for technical rather than commercial reasons, breaking the transformations that you built.1
Now you - or worse, somebody new who has never seen the code before - have to go back and figure out what’s broken, where it’s broken (often in multiple places), and how to fix it.
Even with the right tooling and documentation, this may not be entirely trivial, but when you have no way of understanding the lineage of your data without manually sifting through a bunch of monolithic, spaghetti SQL queries, and without any documentation of what any of it is expected to do, this will fall somewhere between hard and impossible. The technical debt may become so great that the only acceptable option is to bin the code and start from scratch.
dbt: A smartknife for any budget
Knives are dumb. No matter how many times you use one to dice an onion, it won’t learn a thing. Each time, just like the last, you must guide the blade carefully but firmly through the onion’s many layers. There is no compromise. Only tears.
What if you could bark out a simple voice command (“Alexa, I want to cook a risotto!”) and have your knife automatically dice your onions, mince the garlic, portion out the butter, clean the mushrooms and chop them to your desired specification?
What if you could programme the knife to scan the mushrooms for signs of decay, and detect how long the butter has been left out to fester?
What if the knife automatically generated an easily reproducible recipe, with a diagram of the dependencies between all the steps and ingredients?
This “smartknife” is the tool for automating, documenting and quality controlling mise en place within the modern kitchen, ensuring that every ingredient is prepared and laid out for the chefs to cook.
Alexa integration aside, dbt is the smartknife of the modern data team, and led to the popularisation of a new role, the Analytics Engineer. When I joined Impala three years ago, I had never heard of an Analytics Engineer. In 2022, if job boards are to be believed, it’s seemingly unthinkable to build a Data team without Analytics Engineers.
Sitting somewhere between the Data Engineer and the Data Analyst, the Analytics Engineer handles the T (transformation) of the ELT process, and their primary tool is dbt. If the Analytics Engineer were a Pokémon, their signature attack would be “dbt run”.
One reason why both dbt and the Analytics Engineer title have grown so fast is the low barrier to entry. dbt is almost entirely SQL-based (with some Jinja macros), facilitating the transition from Data Analyst to Analytics Engineer (or the overlap between those roles). It also has a good tutorial that will keep you busy for twenty hours or so.
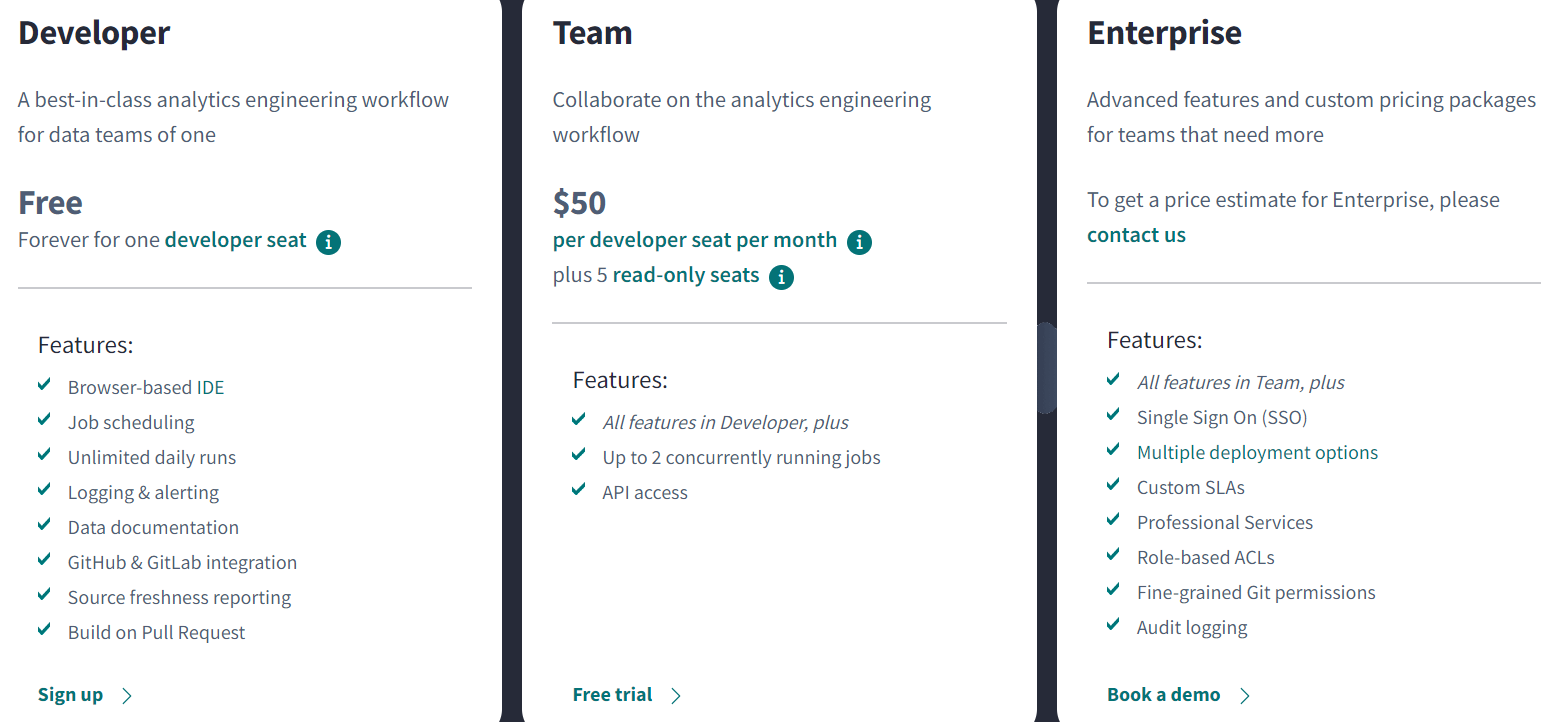
For a single-person Data team, dbt Cloud (the managed version) is free with most of the standard functionality included. This means that, early on, you’ll be able to get a lot of value for nothing. Of course, dbt Cloud benefits from vendor lock-in, and once your team grows, you will most likely switch to the paid “Team” plan at $50 per developer per month, or orchestrate your jobs using Airflow (or another orchestration tool) instead of dbt Cloud. If you use it well, dbt Cloud may be worth it when you weigh that cost against the amount of time saved, and the reduction in pipeline errors and bad data.
You could, if you wanted to, hack together a manual implementation of something vaguely dbt-like for free, without the technical complexity of Airflow. You could schedule transformation jobs - like I did - using scheduled queries. You could manually build data integrity tests, again using scheduled queries (dbt’s testing is all just SQL, after all). You could document all your tables and fields in Google Docs (or Notion, if you’re already paying for it). You could build lineage graphs (or DAGs) in Miro, if you’re already paying for it, or… erm… Google Slides.
All of this is possible, but it will fail, and cost a lot of money in wasted time. Imagine having to remember to update a Miro board every time you tweak a data pipeline or add a new source. If that wasn’t bad enough, imagine an entire team having to remember to do this. That’s before we even get into the lack of visibility of your data lineage, and the time-suck of building every test manually (or, heaven forbid, having no tests). Entropy will take over, disorder will reign supreme, and you’ll be left with a flabby mess of code, tables, and documentation that’s about as edifying to read as a Dan Brown novel.
Using dbt in no way guarantees that these problems will go away. Tests won’t catch every bug. Documentation won’t always be perfect. You will still need to debug things and manually update code. Dan Brown will continue to publish terrible novels. dbt just makes most of these things quicker and easier to deal with.
At enterprise level, where data requirements have matured, and there are business-critical dependencies on ML and reporting, I’m skeptical that the Modern Data Stack approach of sewing together a patchwork of data integration, transformation and reverse ETL2 tools (often in the hands of inexperienced data modellers) is the most effective way to build a data model that scales. However, a small or single-person Data team - especially one operating within an organisation that hasn't yet found product-market fit - is not usually in a position to build scalable infrastructure. dbt, along with other tools I've covered in these posts, offers a low-friction (and mostly low-cost) route to building something that generally works, if you're not yet ready to build something that scales.
Another word of caution: the true cost of dbt does not usually come directly from dbt. The real cost is data warehouse compute costs. If you get carried away with building model upon model upon model upon model upon model ad infinitum, you risk racking up a hefty bill from Snowflake/Databricks/BigQuery/whoever. Use it sparingly, and prune old models that are no longer in use.
What else is there?
By now, you’re probably wondering whether dbt Labs is paying me to write this. They’re not (I have about 8 subscribers lol). I just think that it has a place in most implementations of the Modern Data Stack, is reasonably priced, and has no notable direct competitor to speak of.
Dataform was a direct dbt competitor, but since being acquired by Google in 2020, they aren’t taking new signups until they complete their integration to Google Cloud, and only GCP users will have access to Dataform in future. Dataform Core (the open-source, command line interface-based solution, similar to dbt Core) is still freely available.
There are other tools that may fit somewhere within the workflow, but most would work best alongside dbt rather than as substitutes. For example, Airflow is an open-source, Python-based workflow orchestration tool, which many teams use within the ELT process alongside dbt Core. Airflow is free, widely used, and a great tool for scheduling and monitoring, but it has a much steeper learning curve than dbt Cloud’s managed job orchestration.
Airflow would, of course, be a far superior free tool for building DAGs than Miro or Google Slides, but it presupposes Data Engineering and programming knowledge that a small or one-person team may not have. While I am by no means discouraging the use of Airflow - it is a powerful tool and does what it does well - it adds complexity, and is overkill for many use cases.
Finally, Great Expectations, an open-source tool for data testing and documentation, overlaps with some of dbt’s functionality (and is sometimes used in conjunction with dbt), but does not perform data transformations.
Given that dbt Cloud is free for a single user, saves a lot of time, and only starts to cost money at the point when the DIY approach I described earlier becomes unworkable, a Data team on a tight budget will most likely find that the benefits of dbt Cloud outweigh the modest cost. It may be enhanced with other open-source tools, and you might use dbt Core for free by scheduling jobs with Airflow instead of dbt Cloud, but dbt should be at the centre of any Analytics Engineer’s toolkit.
Or utensil drawer, if it’s not too late to revive that analogy.
This problem can be avoided with data contracts, but these rarely exist at early-stage companies… another topic for another day.
Reverse ETL tools purport to close the feedback loop between data sources and the data warehouse, pushing transformed data back to source for stakeholders across the business to use.