

The Supplier of Everything: Data Integration on a Budget
The Supplier of Everything: Data Integration on a Budget
In this post, I compare the ELT tools Stitch, Fivetran, Airbyte and Matillion. Which offers the most value for money?

In my last post, I likened a cloud data warehouse to a magic fridge that grows and shrinks depending on the amount of food to be stored. Returning to our restaurant analogy, imagine a restaurant that offers dishes inspired by cuisine from around the globe, using authentic ingredients shipped from every continent.
You may question how any chef can claim to have mastered the “authentic” local cuisine of every conceivable region, but most of all, this is a highly complex and time-consuming operation to run.
Because there is no supplier that sells everything you need - many are specialist ingredients, after all - you have to find a multitude of suppliers in various locations, negotiate with them (often in a language you don’t speak), monitor the stock you receive from each supplier, send regular orders, and check that everything arrives on time, in good condition, in the right quantities. It’s unmanageable.
Similarly, because there is no single business that provides every service that a tech company could ever need, it’s normal to have subscriptions across multiple tools (CRM, billing, ad platforms, etc.) to support day-to-day operations.
Most of these services have APIs. This means that our restaurateur can, at the very least, communicate in a common language with their suppliers. However, building multiple API integrations is time-consuming, and not the best use of an analytics team’s time. While most service providers won’t charge you to integrate with their APIs, the cost is felt in the hours spent building integrations, and the opportunity cost of other work not done as a result.
Many Data functions begin with a single mid-level Data Analyst, who may not have the programming expertise to quickly build a dozen API integrations. If they can’t do it, it will usually fall on the Engineering team, whose Product Managers will be loath to spare any capacity, and rightly so given that their Engineers are there to build the product.
Faced with this situation, your best option is to save time and money with a tool that offers a large volume of pre-built integrations to a range of popular web services. Enter the ELT tool.
ELT stands for Extract, Load & Transform, which means moving data from one location to another, then transforming it into an analytics-ready state1. ELT tools are no-code platforms that aim to solve the “data supply” problem by enabling anybody to build an integration between a data source and a data warehouse in minutes. They’ve already built links with your suppliers of white truffles, durians and matsutake mushrooms. All you need to do is tell them which fridge to put them in.

I’ll look at four ELT tools, while keeping cost efficiency front of mind:
Stitch
Fivetran
Airbyte
Matillion
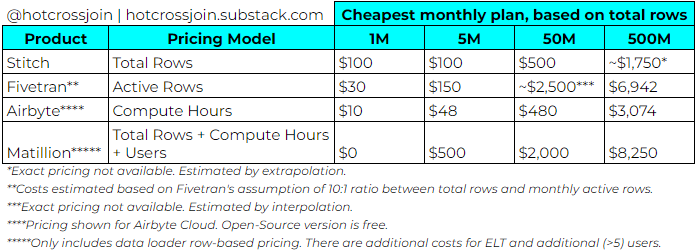
Stitch: cheapest at scale; best value for pure extract & load
I’ve used Stitch for two-and-a-half years. I don’t use it as an ELT tool, but rather an EL tool. It extracts data from various web APIs, loads the data to the warehouse, and that’s it. We handle the transformations separately. Stitch’s website does mention data transformation, but this is a separate product (Data Fabric) offered by their parent company, Talend.
Stitch has the most expensive entry-level tier, but this tier has a generous allowance, and the cost scales relatively slowly. At the lowest ($100/m) pricing tier, you can build up to 10 integrations, and sync up to five million rows of data per month. This suits us at Impala, as we’ve always sat below that 5M threshold, while still getting good utilisation from our quota (3M+ rows per month).
Beyond 5M rows, the price scales non-linearly (i.e. cheaper per row the more you process). Because this row-based model gets expensive across large volumes of data (200M rows will cost you $1k/m), I would recommend only using ELT tools to integrate with web APIs (usually low to moderate volumes), and not with transactional databases.
While Impala’s combined monthly row count from our CRM, billing, accounting and ad platforms is in the low millions, this could easily get out of hand if we were, say, using Stitch to pull every hotel room rate update from our operational database to our data warehouse2. In cases like this, while it may take longer and require engineering resource, it’s generally more sensible to build than to buy.
Stitch can work out cheaper overall if you pay annually (twelve months for the price of ten), but my usual advice is that if you have fewer than twelve months of cash in the bank, don’t purchase any up-front annual licenses that could be paid for monthly, even if it’s cheaper overall. As I gleefully remind my colleagues at regular intervals, cash is king, queen, and disgraced prince.
I’ve never seen a pressing reason to leave Stitch. It’s cost-effective, saves my team time, and works fine. Just be aware that they will try to get you to upgrade every time you log in, even when you’re nowhere near maxing out your quota. They also don’t seem to have realised that they’re not an open-source platform. Whenever an integration breaks, they send me an email suggesting that I fix it. The problem is, most of the errors are things that nobody could fix without access to the code behind the integrations. Weird.
Fivetran: more features than Stitch, but cost scales much faster
Fivetran offers a similar EL product to Stitch. It connects to a comparable range of sources, while also serving as a broader ELT tool. It integrates with dbt Core (a data transformation tool), with pre-built data models designed to give you a more analytics-ready output than what you might get by default from Stitch.
Since business logic varies from company to company, Fivetran’s dbt model for any given source may not fit your use case. For example, at Impala, we sometimes use HubSpot in unusual ways, and I suspect that Fivetran’s interpretation of HubSpot’s API might not be of much use to us.
Fivetran’s cheapest plan is “Standard Select”, which only allows a single user and caps at 500k “monthly active rows”, a term which merits explanation:
Total rows: The total volume of row inserts or updates that occur in a month. This is how Stitch bills.
Monthly active rows: The volume of distinct rows inserted or updated in a month. If a single row is updated multiple times in a month, it is only counted once.
This makes the pricing comparison harder, and forces you to think about the nature of the data that you want to sync. If your syncs involve a lot of updates to existing rows (e.g. changes to the status of a deal in your CRM) and few additional rows, the “monthly active” model may be better value. For transactional data, where lots of immutable rows are added per sync, “monthly active” pricing will be expensive.
Fivetran’s own cost estimates assume a 10:1 ratio between total and monthly active rows. On that basis, if you want more than one user, it is far more expensive than Stitch at 5M rows ($413/month vs $100/month). It does come with more functionality (e.g. dbt integration and analytics-ready schemas), so it depends on what you want from the tool.
Airbyte: the open-source option, with a cheap-ish (US-only) SaaS solution
Airbyte is the only open-source platform of the four. Its integrations are customisable, so similar error messages to Stitch’s would be solvable by the customer.
Airbyte’s free open-source version is not plug-and-play, and requires some configuration, such as setting up Docker and following lengthy walkthroughs (if you haven’t done it before) to get access and refresh tokens for the APIs you want to connect to. So, for an analyst without programming experience, this may be a little daunting, and like many open-source tools, may require heavier maintenance than a SaaS solution.
Airbyte Cloud (the paid, no-code version, only available in the US) is priced at $2.50 per credit, with credits based on compute time (similar to some cloud data warehouses) rather than row volume.
For API sources, Airbyte charges one credit for an hour of compute, which they estimate to be 360k rows. While this depends on a number of factors such as the width of the tables, this would translate to $35/month for 5M rows, which is cheap.
I am inclined to take their pricing estimates with a pinch of salt. Airbyte has a cost estimator, which gives an estimate of the annual cost of Airbyte, based on your expected usage, versus “other row-based ELT tools”. At 5M rows and 5GB of data, they would charge $575 per year ($48 per month). Competitors, so they say, would charge $37,158 per year ($3.1k per month).
This is bullshit. Both Stitch and Fivetran will process that volume of data for a fraction of that price. Even in a fair comparison against their competitors’ actual pricing, Airbyte would still come out cheapest, so I’m unsure what they gain by lying.
Matillion: 🤷♂️
Last - and, as far as I can tell, least - is Matillion. A less mature product than the others on the list, Matillion has a basic UI and, from my limited experience, is not a joy to use. My attempt to set up a simple integration with Gmail failed, and everything felt clunky.
At the time of writing, Matillion’s full ELT solution does not support GCP - it only works with AWS and Azure - but its EL solution works across all three platforms.
Despite its limited functionality, Matillion seems the most expensive. It has a free tier, up to 1M rows across a more limited range of integrations, but beyond that you’re unlikely to get good value. Its pricing model is more opaque than others, with the detail hidden away in a sub-link from the pricing FAQs. As an example though, if you want to load 5M rows, it will cost you $500/month.
Which one to choose?
If you’re in the US and have the time and patience for Airbyte’s heavier open-source configuration, you can probably get what you need for free, until your team grows and you need a more robust SaaS solution, at which point you can upgrade to Airbyte Cloud and still get good value. Just beware the hidden cost of open source. Do your savings on subscription costs really outweigh the additional time spent on setup and maintenance?
Elsewhere, the choice between Stitch and Fivetran may depend on the following:
Whether you need Fivetran’s more extensive features, and whether you’re willing to pay a premium for them.
Whether your data sources are a better fit with the “Total Rows” or “Monthly Active Rows” pricing model.
Matillion, unfortunately, has no selling point for me.
Many people, even vendors themselves, confuse ELT with ETL (note the switching of the T and the L). On-premise data infrastructures, where storage is expensive, typically favour transforming the data before loading into the warehouse to avoid overloading it with redundant data (hence T preceding L). With the rise of cloud data warehouses, and their cheap, elastic storage models, this is less of a concern, and most cloud data transformation now happens after loading the data to the warehouse (hence L preceding T).
Impala is a hotel booking API. We store and update rates for tens of thousands of hotels, each of which has multiple room types and rate plans, with rates for the next 365 days, often changing multiple times per day. When you multiply all of these factors together, you get into hundreds of millions of rows per day.